
自定义函数包含三种UDF, UDAF, UDTF
- UDF(User-Defined-Function):一进一出
- UDAF(User-Defined Aggregation Function):聚集函数,多进一出
- UDTF(User-Defined Table-Generating Functions): 一进多处
使用方式:在HIVE会话中add自定义函数jar文件,然后创建function继而使用函数
自定义函数的步骤(UDF)
- UDF函数可以直接应用于select语句,对查询结构做格式化处理后,再输出内容
- 编写UDF函数的时候需要注意以下几点
- 自定义UDF需要继承
org.apache.hadoop.hive.ql.UDF - 需要实现evaluate函数,evaluate函数支持重载
- 自定义UDF需要继承
以下实现了一个简单的 脱敏工具类,值展示文本的第一个字符即可:
package org.hadoop.hive.learn.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* 只展示第一个字符的操作
*/
public class SensitiveFunc extends UDF {
public String evaluate(String str) {
if (str == null || str.length() <= 1) {
return str;
}
int length = str.length();
String res = str.substring(0,1);
StringBuilder sb = new StringBuilder(res);
for (int i = 1; i < length; i++) {
sb.append("*");
}
return sb.toString();
}
public static void main(String[] args) {
SensitiveFunc sensitiveFunc = new SensitiveFunc();
String res = sensitiveFunc.evaluate("你好劜");
System.out.println(res);
}
}
- 将以上代码打包为jar包,并上传到hive所在服务器中。
- 进入hive客户端,添加jar包
add jar /root/hive-learn-1.0-SNAPSHOT.jar
- 创建临时函数:
create temporary function tuomin as 'org.hadoop.hive.learn.udf.SensitiveFunc'
在创建完成以上的函数之后,就可以使用这个函数了:
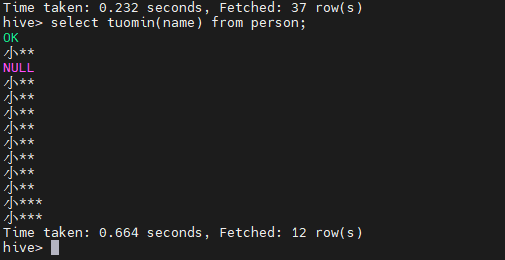
我们可以看到自己定义的脱敏函数已经完成啦~~~~
这样的缺点是,因为创建的时temporary的函数,因此在hive客户端关闭之后,这个函数就无法再次被找到。
在以上的步骤中,我们也可以将jar包上传的hdfs上,然后通过一下命令使用:
create temporary function tumin as 'org.hadoop.hive.learn.udf.SensitiveFunc' using jar 'hdfs://node1:8020/path/tuomin.jar'
创建永久函数
永久函数因为需要使用到jar, 这个时候我们可以将jar包上传到hdfs中,然后创建永久函数,当在任何机器上使用函数时,都可以直接从hdfs上加载jar包并使用,具体步骤如下:
# 创建目录 hdfs dfs -mkdir -p /lib/hive/udf # 上传jar包 hdfs dfs -put /root/hive-learn-1.0-SNAPSHOT.jar /lib/hive/udf/hive-sql-func.jar
然后有了以上的jar包之后,则在Hive客户端,创建永久的函数:
hive> create function sens as 'org.hadoop.hive.learn.udf.SensitiveFunc' using jar 'hdfs://mycluster/lib/hive/udf/hive-sql-func.jar'
有了这个函数之后,我就可以在任何地方使用这个函数了:
一下为在hive的客户端工具查询的情况:
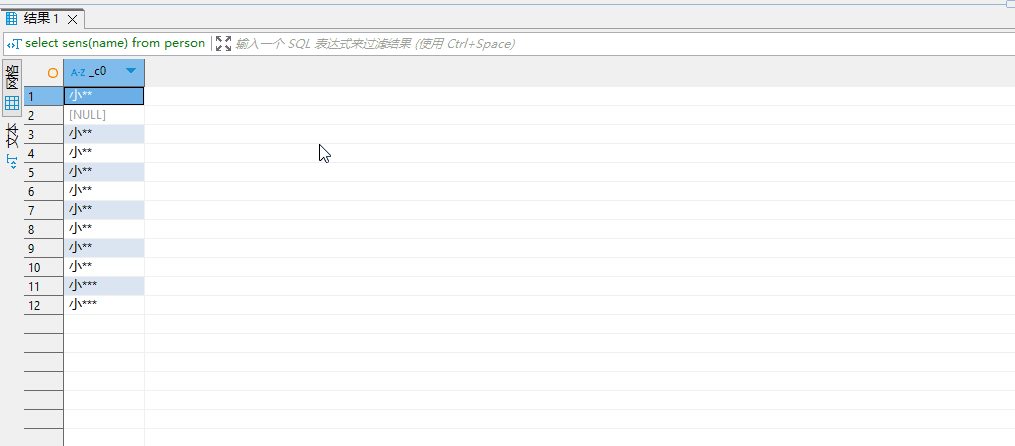
函数的维护
#删除函数名 drop function sens
UDAF自定义集函数
多行进一行出,如sum(), min(),用在group by时
实现步骤如下
- 必须继承
org.apache.hadoop.hive.ql.exec.UDAF(函数类继承)org.apache.hadoop.hive.ql.exec.UDAFEvaluator(内部类 Evaluator实现UDAFEvaluator接口)
- Evaluator需要实现
init,iterate,terminatePartial,merge,terminate这几个函数- init():类似于构造函数,用于UDAF初始化
- iterate():接受传入的参数,并进行内部的轮转,返回boolean
- termiatePartial():无参数,其为iterate函数轮转结束后,返回轮转数据,类似于hadoop的Combiner
- merge():接受terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean
- terminate():返回最终的聚集函数结果
关于UDAF的四个阶段
- PARTIAL1:这个阶段用于接受数据库的原始数据,
iterate()和terminatePartial()方法将被调用。一般指代了mapreduce任务中的map阶段 - PARTIAL2: 这个阶段接受了部分的合并数据,主要是多map阶段产生的数据做合并操作。相当于mapreduce任务中的conbiner. 这个阶段
merge()和terminatePartial()任务将被调用 - FINAL:这个阶段对PARTIAL2产生的数据做整体的合并操作。这个阶段中,
merge()和terminate()方法将被调用。这个阶段就相当于mapreduce任务中的reduce阶段 - COMPLETE:这个阶段就是完结的阶段,
terminate()和iterate()方法将被调用。这个阶段如果mapreduce没有reduce任务,那么将会直接到COMPLETE阶段。这个阶段也是接受的数据库的原始数据
实现concat功能
这段代码主要实现字符串concat功能,实现在group的时候,将对应的字段拼接为一个字符串,具体代码如下:
package org.hadoop.hive.learn.udaf;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.util.ReflectionUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class ConcatStrFunc extends AbstractGenericUDAFResolver {
private static final Logger LOG = LoggerFactory.getLogger(ConcatStrFunc.class);
/**
* 创建Evaluator对象
*
* @param info The types of the parameters. We need the type information to know
* which evaluator class to use.
* @return
* @throws SemanticException
*/
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] info) throws SemanticException {
LOG.info("获取Evaluator对象..");
return new ConcatStrEvaluator();
}
public static class ConcatStrAggregationBuffer implements GenericUDAFEvaluator.AggregationBuffer {
private StringBuilder concatStrBuilder = new StringBuilder();
private Object monitor = new Object();
private static final String SPLITTER = ",";
public ConcatStrAggregationBuffer() {
LOG.info("创建buffer对象..");
}
public ConcatStrAggregationBuffer(String str) {
if (str != null && str.length() > 0) {
concatStrBuilder.append(str);
}
}
public String get() {
return this.concatStrBuilder.toString();
}
public void add(String str) {
if (str == null) {
str = "";
}
synchronized (monitor) {
this.concatStrBuilder.append(SPLITTER).append(str);
}
}
public void reset() {
synchronized (monitor) {
this.concatStrBuilder.delete(0, concatStrBuilder.length());
}
}
}
public static class ConcatStrEvaluator extends GenericUDAFEvaluator {
private PrimitiveObjectInspector inputObjectInspector;
private ObjectInspector outputOI;
public ConcatStrEvaluator() {
}
/**
* 这里主要是用来初始化聚合函数,这里需要对传入的参数进行解析。这个函数在每个阶段都会被调用
*
* @param m The mode of aggregation.
* @param parameters The ObjectInspector for the parameters: In PARTIAL1 and COMPLETE
* mode, the parameters are original data; In PARTIAL2 and FINAL
* mode, the parameters are just partial aggregations (in that case,
* the array will always have a single element).
* @return
* @throws HiveException
*/
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
LOG.info("初始化Evaluator#init()方法...");
super.init(m, parameters);
this.inputObjectInspector = (PrimitiveObjectInspector) parameters[0];
if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) {
// 这里是因为PARTIAL1和COMPLETE阶段都是输入的数据库的原始数据,所以他们的处理逻辑是一样的
} else {
// 这里主要是指代的时对PARTIAL2和FINAL阶段的数据,这里接受到的是上一个阶段计算出的结果,因此这里数据主要来自PARTIAL1和PARTIAL2的结果
}
// 这里是对输出数据的处理,保证我们输出的数据类型和我们需要的类型保持一致
this.outputOI = ObjectInspectorFactory.getReflectionObjectInspector(
String.class,
ObjectInspectorFactory.ObjectInspectorOptions.JAVA
);
return this.outputOI;
}
/**
* 创建buffer对象,用于存储计算的中间结果
*
* @return
* @throws HiveException
*/
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
LOG.info("调用Evaluator#getNewAggregationBuffer()方法...");
return new ConcatStrAggregationBuffer();
}
/**
* 重置buffer中的缓存数据
*
* @param agg
* @throws HiveException
*/
@Override
public void reset(AggregationBuffer agg) throws HiveException {
LOG.info("调用Evaluator#reset()方法...");
((ConcatStrAggregationBuffer) agg).reset();
}
/**
* 遍历数据, 这里因为只会在partial1和COMPLETE中被调用,因此这里遍历的是从数据库中获取的原始数据
*
* @param agg
* @param parameters The objects of parameters.
* @throws HiveException
*/
@Override
public void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException {
LOG.info("调用Evaluator#iterate()方法...");
if (parameters == null || parameters.length == 0) {
return;
}
ConcatStrAggregationBuffer buffer = (ConcatStrAggregationBuffer) agg;
for (Object parameter : parameters) {
buffer.add((String) this.inputObjectInspector.getPrimitiveJavaObject(parameter));
}
}
/**
* 这里调用的是一个阶段性的成果,用于在分布式计算中,将各个mapper的计算结果进行合并
*
* @param agg
* @return
* @throws HiveException
*/
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
LOG.info("调用Evaluator#terminatePartial()");
return this.terminate(agg);
}
@Override
public void merge(AggregationBuffer agg, Object partial) throws HiveException {
LOG.info("调用Evaluator#merge()");
if (partial != null) {
ConcatStrAggregationBuffer buffer = (ConcatStrAggregationBuffer) agg;
// debug info
if (this.inputObjectInspector == null) {
buffer.add("inputObjectInspector is null!");
} else {
buffer.add((String) this.inputObjectInspector.getPrimitiveJavaObject(partial));
}
}
}
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
LOG.info("调用Evaluator#terminate()");
return ConcatStrAggregationBuffer.class.cast(agg).get();
}
}
public static void main(String[] args) {
ConcatStrEvaluator concatStrEvaluator = ReflectionUtils.newInstance(ConcatStrEvaluator.class, new Configuration());
System.out.println(concatStrEvaluator);
}
}
自定义UDAF函数
在有了上面的实现之后,就需要自己定义Hive函数了,这个步骤需要在Hive客户端中进行操作,具体操作步骤如下:
- 将打包好的jar包上传到服务器或者HDFS
- 定义Hive函数
- 使用Hive函数验证
create function s_concat as 'org.hadoop.hive.learn.udaf.ConcatStrFunc' using jar 'hdfs://mycluster/lib/hive/udf/hive-sql-func.jar';
创建完成后,将输出如下的提示,表示函数创建成功:

这里面的输出表示了临时的jar存放的位置,在测试阶段建议使用
create temporary function创建,因为创建永久函数调试程序,如果程序有BUG会导致很多奇怪的问题,在调试好了之后,再创建永久函数
在创建函数完成后,我们就可以使用SQL查询验证是否生效,我的等结果如下:
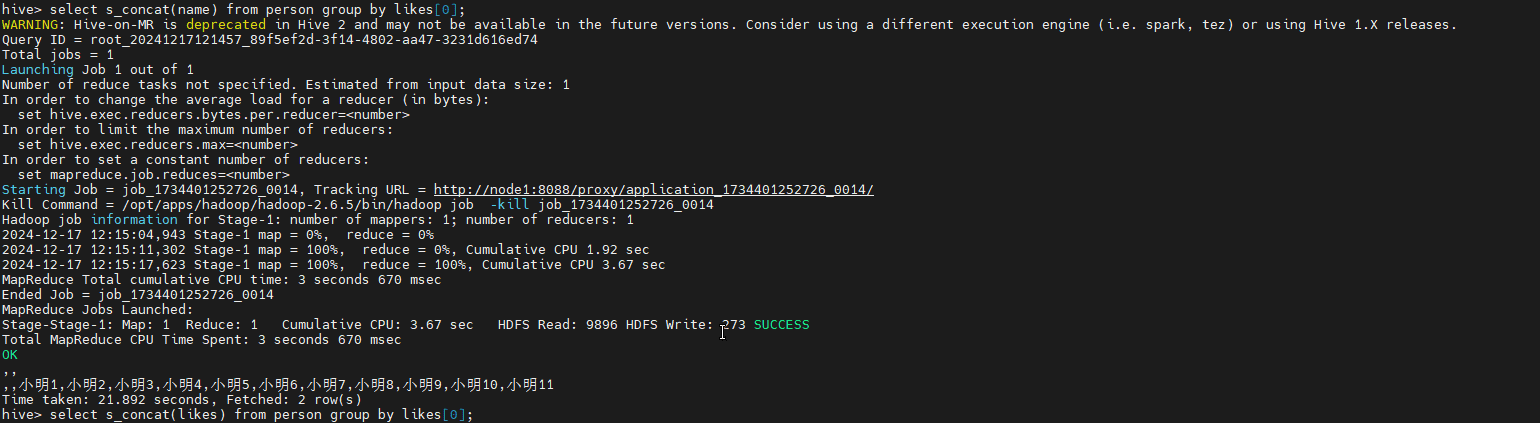
这就表示函数自定完成并成功投入使用。

Pingback: Hive SQL - 专注着的博客