hadoop的集群HA安装,可以参考Hadoop HA集群搭建中进行查看,这里主要是在已有的Hadoop集群上启动yarn, 然后启动集群yarn, 就可以在集群中进行任务的调度和执行。yarn的调度过程,可以参考yarn架构
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 让yarn的容器支持mapreduce的洗牌,开启shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用resoucemanager的HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定zookeeper集群的各个节点地址和端口号 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<!-- 标识集群,以确保RM不会接管另一个集群的活动 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!-- RM HA的两个ResourceManager的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定rm1的resourcemanager进程所在的主机名称 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<!-- 指定rm2的resourcemanager进程所在的主机名称 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!--指定mr作业运行的框架:要么本地运行,要么使用classic(MRv1),要么使用yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
这里主要配置了在任性任务调度的时候,使用yarn进行任务的调度,这样就可以使用yarn了
启动yarn
启动yarn则不会像启动dfs那样可以通过ssh的方式启动,我们可以通过脚本的方式启动yarn:
#!/bin/bash
for node in node1 node2 node3
do
ssh $node "source /etc/profile; zkServer.sh start"
done
sleep 1
start-dfs.sh
start-yarn.sh
for node in node4
do
ssh $node "source /etc/profile; start-yarn.sh"
done
echo "----------------node1-jps------------------------"
jps
for node in node2 node3 node4
do
echo "--------------------------${node}-jps-----------------"
ssh $node "source /etc/profile; jps"
done
这里就主要通过ssh的方式去启动yarn和dfs,并查看启动的状态,以上就是yarn的简单配置,这样我们就可以访问集群了。
验证是否成功
从上面配置可以知道,我们可以通过访问node1和Node4查看yarn的启动情况。通过访问8088端口,查看集群启动情况,如果启动正常,则会展示一下界面:
以下为node1的界面情况:
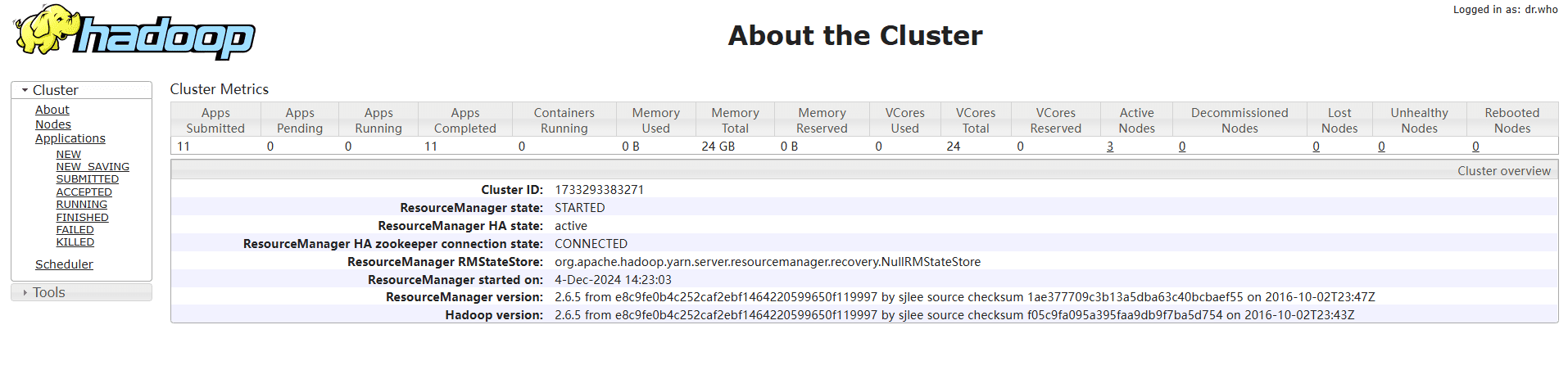 以下为node4的界面情况:
以下为node4的界面情况:

因为node4是standby的角色,因此在访问node4的8088端口时,会自动的跳转到node1的地址。
以上就是yarn简单配置,这样我们就可以开发mapreduce的任务啦~~~~
创建任务并执行
这里主要实现一个单词统计的功能,主要代码如下:
pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.5</version>
</dependency>
WordCountMapper
package org.hadoop.learn.mp.wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 第一个参数KEYIN: 读取文件的偏移量
* 第二个参数VALUEIN: 代表了这一行的文本内容,输入的value类型
* 第三个参数KEYOUT: 输出的key的value类型
* 第四个擦拿书VALUEOUT 输出的value类型
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable inKey, Text inValue, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
Thread.sleep(10000000);
// 获取当前行文本内容
String line = inValue.toString();
// 按照空行进行拆分
String[] words = line.split(" ");
for (String word : words) {
if (word.isEmpty()) {
continue;
}
context.write(new Text(word), new LongWritable(1));
}
}
}
WordCountReducer
package org.hadoop.learn.mp.wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// 定义当前单词出现的总次数
long sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
}
WordCountMain
package org.hadoop.learn.mp.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import java.io.IOException;
public class WordCountMain {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
if (args == null || args.length == 0 || args.length != 2) {
System.out.println("请输入输入/输出路径");
return;
}
System.setProperty("HADOOP_HOME", "H:\\xianglujun\\hadoop-2.6.5");
System.setProperty("hadoop.home.dir", "H:\\xianglujun\\hadoop-2.6.5");
System.setProperty("HADOOP_USER_NAME", "root");
Configuration configuration = new Configuration();
// 设置本地运行
configuration.set("mapreduce.framework.name", "local");
JobConf jobConf = new JobConf(configuration);
// 设置作业的输入输出路径
FileInputFormat.addInputPath(jobConf, new Path(args[0]));
Path outputPath = new Path(args[1]);
FileOutputFormat.setOutputPath(jobConf, outputPath);
Job job = Job.getInstance(jobConf);
FileSystem fs = FileSystem.get(configuration);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
job.setJarByClass(WordCountMain.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setJobName("wordcount");
// 设置输出key的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 设置reducer的相关
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 提交作业并等待作业结束
boolean b = job.waitForCompletion(true);
System.out.println("任务是否执行完成: " + b);
}
}
为了能够执行起来,需要做一下步骤:
- 在通过hadoop集群运行的时候,需要取消本地运行的配置哦
mapreduce.framework.name - 将以上代码使用maven打包为jar, 并上传到hadoop的服务器
- 然后通过yarn的方式执行代码
yarn jar hedoop-learn-1.0-SNAPSHOT.jar org.hadoop.learn.mp.temporary.WeatherMain /xianglujun/tmpr/list.txt /xianglujun/tmpr/result - 在hadoop的hdfs中查看结果输出,检验结果。
以上执行完毕,希望可以帮助到大家。。